汉王PDF OCR8.1简体中文版下载|汉王OCR文字识别软件 V8.1 免费中文版下载
汉王PDF OCR8.1简体中文版是一款非常好用的OCR文字识别软件,软件支持文字型PDF的直接转换和图像型PDF的OCR识别,知识兔可以采用PCR的方式将PDF文件转换为可编辑文档,知识兔也可以采用格式转换的方式直接转换文字型PDF文件为文本。
知识兔小编精选:OCR文字识别软件
【功能特点】
1、识别正确率高,识别速度快、批量处理功能;
2、支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件;
3、可识别简体、繁体和英文三种语言;
4、具有简单易用的表格识别功能;
5、具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功能。
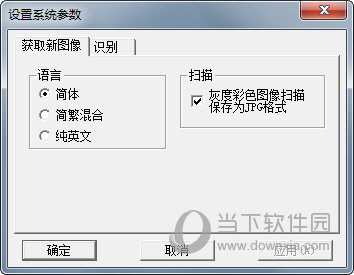
【使用说明】
1、首先直接打开“HWPDFOCR80.exe”汉王PDF OCR;
2、知识兔点击“文件”-“图像”(或直接按快捷键ctrl+O);
3、在弹出的对话框中选择PDF文件,此时下方的“pdf转换为TXT文件”或“pdf转换为RTF文件”将由灰变黑为可操作。
【常见问答】
一、汉王文字识别软件可以识别英文吗?
1、可以,识别之前,在菜单或者工具栏里面设置一下是识别中文或英文。
二、为什么用汉王OCR识别的文字都是乱码?
1、可能是图片不清晰,扫描的时候调整一下分辨率。高级选项也可以设置一下大小。
三、用汉王PDF OCRV8.0 把pdf文件转换成TXT不成功?
因你的PDF文件是图形格式,不能直接转换(转换了也是空白的),需要用OCR识别。识别前进行OCR识别设置,语言和灰度设置。
使用方法:
1.知识兔打开汉王(设置),知识兔打开PDF文件,提示拆分页,确定,就自动识别页和拆分页。
2.再选择第1页,按住SHIFT,用鼠标滑动到最后一页,知识兔选择最后1页,相当于全部选择页;
3.按F8开始自动识别,会识别到 \My Documents\My Hwdoc Files\HWPDFOCR80\IMAGE 目录下;
4.因是按页识别的,要合并TXT文件。
在识别的TXT文件目录(\My Documents\My Hwdoc Files\HWPDFOCR80\IMAGE 目录下)下,建立一个纯文件文件,比如取名为:合并.TXT,改扩展名为BAT:合并.BAT
选择,鼠标右键,知识兔选择编辑,知识兔输入1个语句:
“copy *.txt 合并.txt”或“type *.txt >> 合并.txt”
两种方法都可以,知识兔选择一种就行,保存退出;知识兔双击这个批处理程序,就把当前目录下所有单页TXT文件,合并成1个TXT文件。记住只知识兔点击一次就行了,知识兔点击多了会重复合并。
识别完图片文字后导出时选择“输出”——“到指定格式文件”——选择“保存类型为RTF文件”,这样导出来就可以直接变成可编辑的WORD文件了,版面也一样。
下载仅供下载体验和测试学习,不得商用和正当使用。

![PICS3D 2020破解版[免加密]_Crosslight PICS3D 2020(含破解补丁)](/d/p156/2-220420222641552.jpg)