MoeTTS V1.1.1 最新版下载
MoeTTS是一款Tacotron2/HifiGAN模型+编译好的GUI版本发布仓库,训练时长3天,约900 Epoch,13人大型模型还在训练中,之后也会发布至MoeTTS项目页,视频后面的模型400 Epoch训练了5天,语音合成大部分角色效果很好了,数据较少的几个角色还不太行。
【使用说明】
模型目录格式
单模型可以放在任意位置,如果知识兔模型带有配置文件,请将它重命名为config.json并与TTS模型放置在同一目录。(例如hifigan,vits模型,它们是带有配置文件的)
VITS模型请将config.json中的cleaners 改为custom_cleaners
文本输入格式
文本一般是输入音素(日语在这里应该输入罗马音),但具体要看模型训练者的数据是怎么输入的。比如我的ATRI模型(Tacotron2版本)是输入无空格罗马音,标点符号只支持逗号句号。
自定义Cleaner与Symbols
你可以在与moetts.exe同级的目录下找到custom文件夹,这里面存放了两种模型的文本模块。
自定义cleaner:找到cleaners.py并修改custom_cleaners函数即可(软件默认只会移除不在symbols中的字符,不对文本做进一步处理)
自定义symbols:找到symbols.py,将里面的符号为你需要的符号
注意:不同模型可能使用不同的cleaners与symbols训练,有需要请修改他们,保证模型能正常使用。

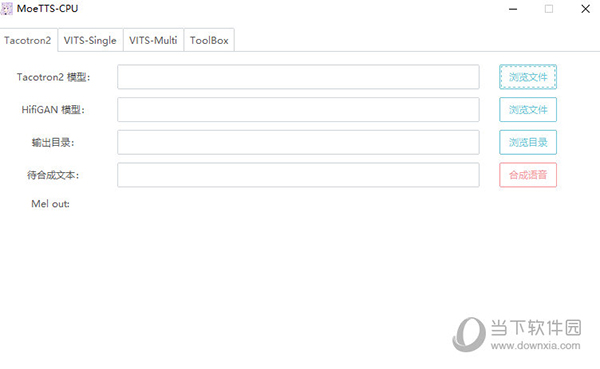
GUI使用方法
tacotron2
选择您的模型路径与输出目录,最后输入待合成文本,知识兔点击合成语音等待一会软件会将音频输出到输出目录/outpus.wav
注意事项:
首次合成需要加载模型,耗时较长,相同模型再次合成不会再次加载,直接合成。
如果知识兔切换模型,再次合成会重新加载。
如果知识兔修改cleaners与symbols,重新启动软件后才能生效。
软件为64位版本,不支持32位系统。
VITS特殊说明
VITS-Single,VITS-Multi分别为单角色模型与多角色模型
VITS-Multi中的原角色ID即待合成语音的角色ID,需要填入数字,目标角色ID为语音迁移功能的待迁移目标角色ID。
待迁移音频需要22050的采样率,16位,单声道。
下载仅供下载体验和测试学习,不得商用和正当使用。

![PICS3D 2020破解版[免加密]_Crosslight PICS3D 2020(含破解补丁)](/d/p156/2-220420222641552.jpg)